About Me
I am a PhD candidate at the Nanjing University, specializing in Deep Learning and Computer Vision. I work under the supervision of Prof.Sanglu LU and assistant professor Yafeng Yin. My PhD research centers on Sign Language Recognition and Sign Language Translation, encompassing two primary domains: Computer Vision and Multimodal Learning. Broadly speaking, my investigations aim to convert video sequences into text, and to learn human acition representations from videos with CV model and NLP model. I am also interest in LVMs.
Research
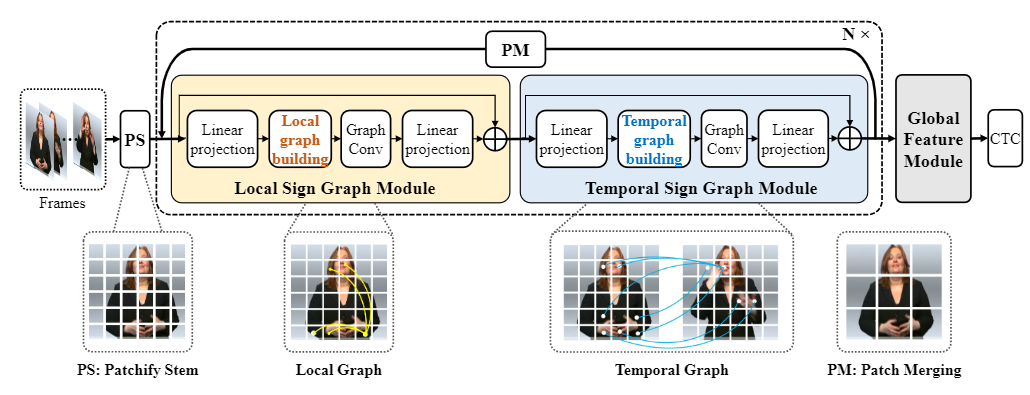
We propose to represent a sign sequence as graphs and introduce a simple yet effective graph-based sign language processing architecture named SignGraph, to extract cross-region features at the graph level. SignGraph consists of two basic modules: Local Sign Graph (LSG) module for learning the correlation of intra-frame cross-region features in one frame and Temporal Sign Graph (TSG) module for tracking the interaction of inter-frame cross-region features among adjacent frames. With LSG and TSG, we build our model in a multiscale manner to ensure that the representation of nodes can capture cross-region features at different granularities. Extensive experiments on current public sign language datasets demonstrate the superiority of our SignGraph model. Our model achieves very competitive performances with the SOTA model, while not using any extra cues. Code and models are available at:
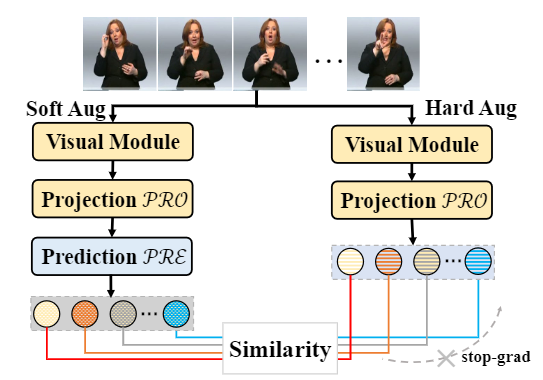
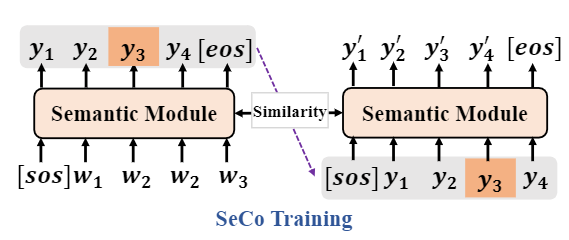
In this paper, we tackle CTC spike phenomenon and exposure bias by introducing contrast learning for CSLR and SLT, aiming to enhance both visual-level feature representation and semantic-level error tolerance. Specifically, to alleviate CTC spike phenomenon and enhance visual-level representation, we design a visual contrastive loss by minimizing visual feature distance between different augmented samples of frames in one sign video, so that the model can further explore features by utilizing numerous unlabeled frames in an unsupervised way. To alleviate exposure bias problem and improve semantic-level error tolerance, we design a semantic contrastive loss by re-inputting the predicted sentence into semantic module and comparing features of ground-truth sequence and predicted sequence, for exposing model to its own mistakes. Besides, we propose two new metrics, i.e., Blank Rate and Consecutive WrongWord Rate to directly reflect our improvement on the two problems.
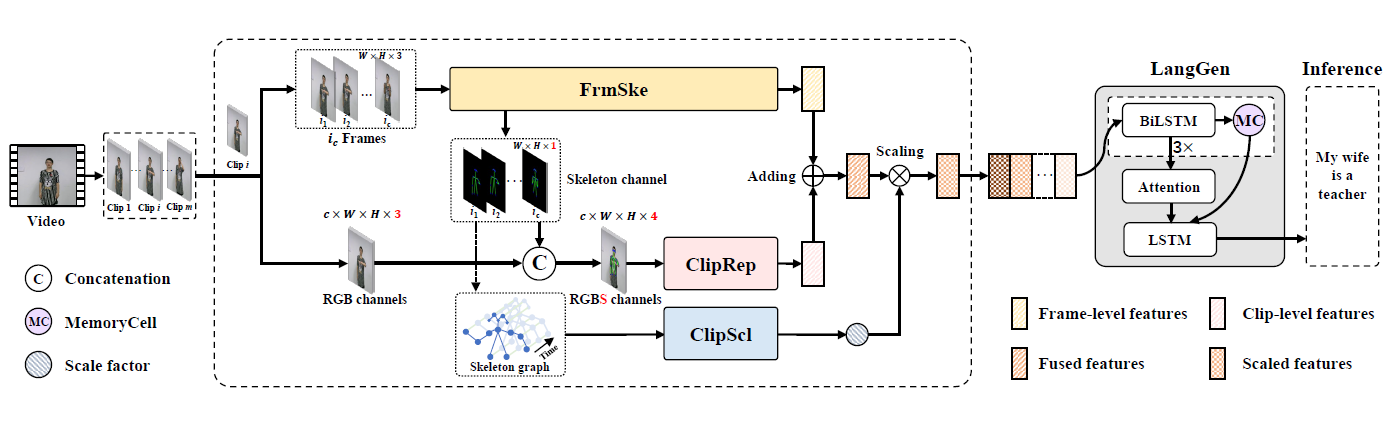
As an essential communication way for deaf-mutes, sign languages are expressed by human actions. To distinguish human actions for sign language understanding, the skeleton which contains position information of human pose can provide an important cue, since different actions usually correspond to different poses/skeletons. However, skeleton has not been fully studied for Sign Language Translation (SLT), especially for end-to-end SLT. Therefore, in this paper, we propose a novel end-to-end Skeleton-Aware neural Network (SANet) for video-based SLT. Specifically, to achieve end-toend SLT, we design a self-contained branch for skeleton extraction. To efficiently guide the feature extraction from video with skeletons, we concatenate the skeleton channel and RGB channels of each frame for feature extraction. To distinguish the importance of clips, we construct a skeleton-based Graph Convolutional Network (GCN) for feature scaling, i.e., giving importance weight for each clip. The scaled features of each clip are then sent to a decoder module to generate spoken language. In our SANet, a joint training strategy is designed to optimize skeleton extraction and sign language translation jointly.
Education
Visiting student sponsored by CSC Scholarship
Advised by Professor Hongkai Wen
Advised by Professor Sanglu Lu and Associate Researcher Yafeng Yin
Thesis: Sign Language Recognition and Translation
Average score: 87.26/100.
Rank: 4/184 (Top 3.26%)
Experience
Invigilator
The University of Warwick 2024
Teaching Assistant
Course: CS933-15 Image and Video Analysis, The University of WarwickFall 2023
Course: Computer Network, Nanjing UniversitySpring 2024
Course: Data Structure, Nanjing University 2019-2022
